|
| 1 | +# RAGulate |
| 2 | + |
| 3 | +A tool for evaluating RAG pipelines |
| 4 | + |
| 5 | + |
| 6 | + |
| 7 | +## The Metrics |
| 8 | + |
| 9 | +The RAGulate currently reports 4 relevancy metrics: Answer Correctness, Answer Relevance, Context Relevance, and Groundedness. |
| 10 | + |
| 11 | + |
| 12 | +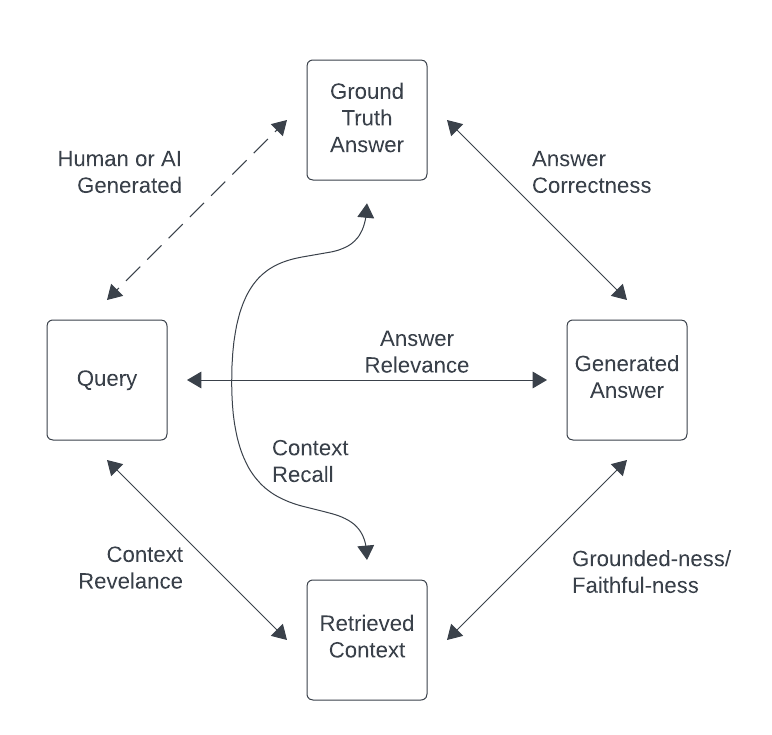 |
| 13 | + |
| 14 | +* Answer Correctness |
| 15 | + * How well does the generated answer match the ground-truth answer? |
| 16 | + * This confirms how well the full system performed. |
| 17 | +* Answer Relevance |
| 18 | + * Is the generated answer relevant to the query? |
| 19 | + * This shows if the LLM is responding in a way that is helpful to answer the query. |
| 20 | +* Context Relevance: |
| 21 | + * Does the retrieved context contain information to answer the query? |
| 22 | + * This shows how well the retrieval part of the process is performing. |
| 23 | +* Groundedness: |
| 24 | + * Is the generated response supported by the context? |
| 25 | + * Low scores here indicate that the LLM is hallucinating. |
| 26 | + |
| 27 | +## Example Output |
| 28 | + |
| 29 | +The tool outputs results as images like this: |
| 30 | + |
| 31 | +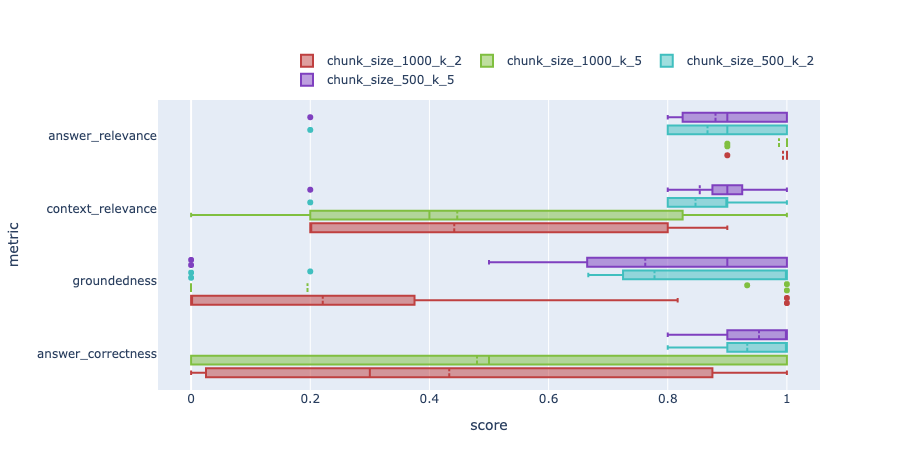 |
| 32 | + |
| 33 | +These images show distribution box plots of the metrics for different test runs. |
| 34 | + |
| 35 | +## Installation |
| 36 | + |
| 37 | +```sh |
| 38 | +pip install ragulate |
| 39 | +``` |
| 40 | + |
| 41 | +## Initial Setup |
| 42 | + |
| 43 | +1. Set your environment variables or create a `.env` file. You will need to set `OPENAI_API_KEY` and |
| 44 | + any other environment variables needed by your ingest and query pipelines. |
| 45 | + |
| 46 | +1. Wrap your ingest pipeline in a single python method. The method should take a `file_path` parameter and |
| 47 | + any other variables that you will pass during your experimentation. The method should ingest the passed |
| 48 | + file into your vector store. |
| 49 | + |
| 50 | + See the `ingest()` method in [open_ai_chunk_size_and_k.py](open_ai_chunk_size_and_k.py) as an example. |
| 51 | + This method configures an ingest pipeline using the parameter `chunk_size` and ingests the file passed. |
| 52 | + |
| 53 | +1. Wrap your query pipeline in a single python method, and return it. The method should have parameters for |
| 54 | + any variables that you will pass during your experimentation. Currently only LangChain LCEL query pipelines |
| 55 | + are supported. |
| 56 | + |
| 57 | + See the `query()` method in [open_ai_chunk_size_and_k.py](open_ai_chunk_size_and_k.py) as an example. |
| 58 | + This method returns a LangChain LCEL pipeline configured by the parameters `chunk_size` and `k`. |
| 59 | + |
| 60 | +Note: It is helpful to have a `**kwargs` param in your pipeline method definitions, so that if extra params |
| 61 | + are passed, they can be safely ignored. |
| 62 | + |
| 63 | +## Usage |
| 64 | + |
| 65 | +### Summary |
| 66 | + |
| 67 | +```sh |
| 68 | +usage: ragulate [-h] {download,ingest,query,compare} ... |
| 69 | + |
| 70 | +RAGu-late CLI tool. |
| 71 | + |
| 72 | +options: |
| 73 | + -h, --help show this help message and exit |
| 74 | + |
| 75 | +commands: |
| 76 | + download Download a dataset |
| 77 | + ingest Run an ingest pipeline |
| 78 | + query Run an query pipeline |
| 79 | + compare Compare results from 2 (or more) recipes |
| 80 | + run Run an experiment from a config file |
| 81 | +``` |
| 82 | + |
| 83 | +### Example |
| 84 | + |
| 85 | +For the examples below, we will use the example experiment [open_ai_chunk_size_and_k.py](open_ai_chunk_size_and_k.py) |
| 86 | +and see how the RAG metrics change for changes in `chunk_size` and `k` (number of documents retrieved). |
| 87 | + |
| 88 | +There are two ways to run Ragulate to run an experiment. Either define an experiment with a config file or execute it manually step by step. |
| 89 | + |
| 90 | +#### Via Config File |
| 91 | + |
| 92 | +**Note: Running via config file is a new feature and it is not as stable as running manually.** |
| 93 | + |
| 94 | +1. Create a yaml config file with a similar format to the example config: [example_config.yaml](example_config.yaml). This defines the same test as shown manually below. |
| 95 | + |
| 96 | +1. Execute it with a single command: |
| 97 | + |
| 98 | + ``` |
| 99 | + ragulate run example_config.yaml |
| 100 | + ``` |
| 101 | +
|
| 102 | + This will: |
| 103 | + * Download the test datasets |
| 104 | + * Run the ingest pipelines |
| 105 | + * Run the query pipelines |
| 106 | + * Output an analysis of the results. |
| 107 | +
|
| 108 | +
|
| 109 | +#### Manually |
| 110 | +
|
| 111 | +1. Download a dataset. See available datasets here: https://llamahub.ai/?tab=llama_datasets |
| 112 | + * If you are unsure where to start, recommended datasets are: |
| 113 | + * `BraintrustCodaHelpDesk` |
| 114 | + * `BlockchainSolana` |
| 115 | +
|
| 116 | + Examples: |
| 117 | + * `ragulate download -k llama BraintrustCodaHelpDesk` |
| 118 | + * `ragulate download -k llama BlockchainSolana` |
| 119 | +
|
| 120 | +2. Ingest the datasets using different methods: |
| 121 | +
|
| 122 | + Examples: |
| 123 | + * Ingest with `chunk_size=200`: |
| 124 | + ``` |
| 125 | + ragulate ingest -n chunk_size_200 -s open_ai_chunk_size_and_k.py -m ingest \ |
| 126 | + --var-name chunk_size --var-value 200 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 127 | + ``` |
| 128 | + * Ingest with `chunk_size=100`: |
| 129 | + ``` |
| 130 | + ragulate ingest -n chunk_size_100 -s open_ai_chunk_size_and_k.py -m ingest \ |
| 131 | + --var-name chunk_size --var-value 100 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 132 | + ``` |
| 133 | +
|
| 134 | +3. Run query and evaluations on the datasets using methods: |
| 135 | +
|
| 136 | + Examples: |
| 137 | + * Query with `chunk_size=200` and `k=2` |
| 138 | + ``` |
| 139 | + ragulate query -n chunk_size_200_k_2 -s open_ai_chunk_size_and_k.py -m query_pipeline \ |
| 140 | + --var-name chunk_size --var-value 200 --var-name k --var-value 2 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 141 | + ``` |
| 142 | +
|
| 143 | + * Query with `chunk_size=100` and `k=2` |
| 144 | + ``` |
| 145 | + ragulate query -n chunk_size_100_k_2 -s open_ai_chunk_size_and_k.py -m query_pipeline \ |
| 146 | + --var-name chunk_size --var-value 100 --var-name k --var-value 2 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 147 | + ``` |
| 148 | +
|
| 149 | + * Query with `chunk_size=200` and `k=5` |
| 150 | + ``` |
| 151 | + ragulate query -n chunk_size_200_k_5 -s open_ai_chunk_size_and_k.py -m query_pipeline \ |
| 152 | + --var-name chunk_size --var-value 200 --var-name k --var-value 5 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 153 | + ``` |
| 154 | +
|
| 155 | + * Query with `chunk_size=100` and `k=5` |
| 156 | + ``` |
| 157 | + ragulate query -n chunk_size_100_k_5 -s open_ai_chunk_size_and_k.py -m query_pipeline \ |
| 158 | + --var-name chunk_size --var-value 100 --var-name k --var-value 5 --dataset BraintrustCodaHelpDesk --dataset BlockchainSolana |
| 159 | + ``` |
| 160 | +
|
| 161 | +1. Run a compare to get the results: |
| 162 | +
|
| 163 | + Example: |
| 164 | + ``` |
| 165 | + ragulate compare -r chunk_size_100_k_2 -r chunk_size_200_k_2 -r chunk_size_100_k_5 -r chunk_size_200_k_5 |
| 166 | + ``` |
| 167 | +
|
| 168 | + This will output 2 png files. one for each dataset. |
| 169 | +
|
| 170 | +## Current Limitations |
| 171 | +
|
| 172 | +* The evaluation model is locked to OpenAI gpt3.5 |
| 173 | +* Only LangChain query pipelines are supported |
| 174 | +* Only LlamaIndex datasets are supported |
| 175 | +* There is no way to specify which metrics to evaluate. |
0 commit comments