|
26 | 26 | "* The model comes with a new refined depth architecture capable of preserving context from prior generation layers in an image-to-image setting. This structure preservation helps generate images that preserving forms and shadow of objects, but with different content.\n", |
27 | 27 | "* The model comes with an updated inpainting module built upon the previous model. This text-guided inpainting makes switching out parts in the image easier than before.\n", |
28 | 28 | "\n", |
29 | | - "This notebook demonstrates how to download the model from the Hugging Face Hub and converted to OpenVINO IR format with [Optimum Intel](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion). And how to use the model to generate sequence of images for infinite zoom video effect.\n", |
| 29 | + "This notebook demonstrates how to download the model from the Hugging Face Hub and convert to OpenVINO IR format with the [Hugging Face Optimum Intel](https://huggingface.co/docs/optimum/intel/index) library. And how to use the model to generate sequence of images for infinite zoom video effect using [OpenVINO GenAI](https://github.com/openvinotoolkit/openvino.genai) that provides easy-to-use API.\n", |
30 | 30 | "\n", |
31 | 31 | "\n", |
32 | 32 | "<img referrerpolicy=\"no-referrer-when-downgrade\" src=\"https://static.scarf.sh/a.png?x-pxid=5b5a4db0-7875-4bfb-bdbd-01698b5b1a77&file=notebooks/stable-diffusion-v2/stable-diffusion-v2-infinite-zoom.ipynb\" />\n" |
|
103 | 103 | "metadata": {}, |
104 | 104 | "outputs": [], |
105 | 105 | "source": [ |
106 | | - "%pip install -q \"diffusers>=0.14.0\" \"transformers>=4.25.1\" \"gradio>=4.19\" \"openvino>=2024.2.0\" \"torch>=2.1\" Pillow opencv-python \"git+https://github.com/huggingface/optimum-intel.git\" --extra-index-url https://download.pytorch.org/whl/cpu" |
| 106 | + "%pip install -q -U \"openvino>=2025.0\" \"openvino-genai>=2025.0\"\n", |
| 107 | + "%pip install -q \"diffusers>=0.14.0\" \"transformers>=4.25.1\" \"gradio>=4.19\" \"torch>=2.1\" Pillow opencv-python \"git+https://github.com/huggingface/optimum-intel.git\" --extra-index-url https://download.pytorch.org/whl/cpu" |
107 | 108 | ] |
108 | 109 | }, |
109 | 110 | { |
|
115 | 116 | "## Load Stable Diffusion Inpaint pipeline using Optimum Intel\n", |
116 | 117 | "[back to top ⬆️](#Table-of-contents:)\n", |
117 | 118 | "\n", |
118 | | - "We will load optimized Stable Diffusion model from the Hugging Face Hub and create pipeline to run an inference with OpenVINO Runtime by [Optimum Intel](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion). \n", |
| 119 | + "[stable-diffusion-2-inpainting](https://huggingface.co/stabilityai/stable-diffusion-2-inpainting) is available for downloading via the [HuggingFace hub](https://huggingface.co/models). We will use optimum-cli interface for exporting it into OpenVINO Intermediate Representation (IR) format.\n", |
119 | 120 | "\n", |
120 | | - "For running the Stable Diffusion model with Optimum Intel, we will use the optimum.intel.OVStableDiffusionInpaintPipeline class, which represents the inference pipeline. OVStableDiffusionInpaintPipeline initialized by the from_pretrained method. It supports on-the-fly conversion models from PyTorch using the export=True parameter. A converted model can be saved on disk using the save_pretrained method for the next running. \n", |
| 121 | + " Optimum CLI interface for converting models supports export to OpenVINO (supported starting optimum-intel 1.12 version).\n", |
| 122 | + "General command format:\n", |
| 123 | + "\n", |
| 124 | + "```bash\n", |
| 125 | + "optimum-cli export openvino --model <model_id_or_path> --task <task> <output_dir>\n", |
| 126 | + "```\n", |
| 127 | + "\n", |
| 128 | + "where `task` is the task to export the model for, if not specified, the task will be auto-inferred based on the model.\n", |
| 129 | + "\n", |
| 130 | + "You can find a mapping between tasks and model classes in Optimum TaskManager [documentation](https://huggingface.co/docs/optimum/exporters/task_manager).\n", |
| 131 | + "\n", |
| 132 | + "Additionally, you can specify weights compression `--weight-format` for the model compression. Please note, that for INT8/INT4, it is necessary to install nncf.\n", |
| 133 | + "\n", |
| 134 | + "Full list of supported arguments available via `--help`\n", |
| 135 | + "For more details and examples of usage, please check [optimum documentation](https://huggingface.co/docs/optimum/intel/inference#export).\n", |
| 136 | + "\n", |
| 137 | + "\n", |
| 138 | + "For running the Stable Diffusion model, we will use [OpenVINO GenAI](https://github.com/openvinotoolkit/openvino.genai) that provides easy-to-use API for running text generation. Firstly we will create pipeline with `InpaintingPipeline`. You can see more details in [Image Python Generation Pipeline Example](https://github.com/openvinotoolkit/openvino.genai/tree/releases/2025/0/samples/python/image_generation#run-inpainting-pipeline).\n", |
| 139 | + "Then we run the `generate` method and get the image tokens and then convert them into the image using `Image.fromarray` from PIL. Also we convert the input images to `ov.Tensor` using `image_to_tensor` function. \n", |
121 | 140 | "\n", |
122 | 141 | "Select device from dropdown list for running inference using OpenVINO." |
123 | 142 | ] |
|
138 | 157 | " )\n", |
139 | 158 | " open(\"notebook_utils.py\", \"w\").write(r.text)\n", |
140 | 159 | "\n", |
| 160 | + "if not Path(\"cmd_helper.py\").exists():\n", |
| 161 | + " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/cmd_helper.py\")\n", |
| 162 | + " open(\"cmd_helper.py\", \"w\").write(r.text)\n", |
| 163 | + "\n", |
141 | 164 | "# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry\n", |
142 | 165 | "from notebook_utils import collect_telemetry\n", |
143 | 166 | "\n", |
|
157 | 180 | "metadata": {}, |
158 | 181 | "outputs": [], |
159 | 182 | "source": [ |
160 | | - "from optimum.intel.openvino import OVStableDiffusionInpaintPipeline\n", |
161 | | - "from pathlib import Path\n", |
| 183 | + "import openvino as ov\n", |
| 184 | + "\n", |
| 185 | + "from cmd_helper import optimum_cli\n", |
162 | 186 | "\n", |
163 | | - "DEVICE = device.value\n", |
164 | 187 | "\n", |
165 | 188 | "MODEL_ID = \"stabilityai/stable-diffusion-2-inpainting\"\n", |
166 | 189 | "MODEL_DIR = Path(\"sd2_inpainting\")\n", |
167 | 190 | "\n", |
168 | | - "if not MODEL_DIR.exists():\n", |
169 | | - " ov_pipe = OVStableDiffusionInpaintPipeline.from_pretrained(MODEL_ID, export=True, device=DEVICE, compile=False)\n", |
170 | | - " ov_pipe.save_pretrained(MODEL_DIR)\n", |
171 | | - "else:\n", |
172 | | - " ov_pipe = OVStableDiffusionInpaintPipeline.from_pretrained(MODEL_DIR, device=DEVICE, compile=False)\n", |
| 191 | + "optimum_cli(MODEL_ID, MODEL_DIR, additional_args={\"weight-format\": \"fp16\"})" |
| 192 | + ] |
| 193 | + }, |
| 194 | + { |
| 195 | + "cell_type": "code", |
| 196 | + "execution_count": null, |
| 197 | + "id": "a424af25", |
| 198 | + "metadata": {}, |
| 199 | + "outputs": [], |
| 200 | + "source": [ |
| 201 | + "import openvino_genai as ov_genai\n", |
173 | 202 | "\n", |
174 | | - "ov_pipe.compile()" |
| 203 | + "\n", |
| 204 | + "pipe = ov_genai.InpaintingPipeline(MODEL_DIR, device.value)" |
175 | 205 | ] |
176 | 206 | }, |
177 | 207 | { |
|
184 | 214 | "[back to top ⬆️](#Table-of-contents:)\n", |
185 | 215 | "\n", |
186 | 216 | "For achieving zoom effect, we will use inpainting to expand images beyond their original borders.\n", |
187 | | - "We run our `OVStableDiffusionInpaintPipeline` in the loop, where each next frame will add edges to previous. The frame generation process illustrated on diagram below:\n", |
| 217 | + "We run our `InpaintingPipeline` in the loop, where each next frame will add edges to previous. The frame generation process illustrated on diagram below:\n", |
188 | 218 | "\n", |
189 | 219 | "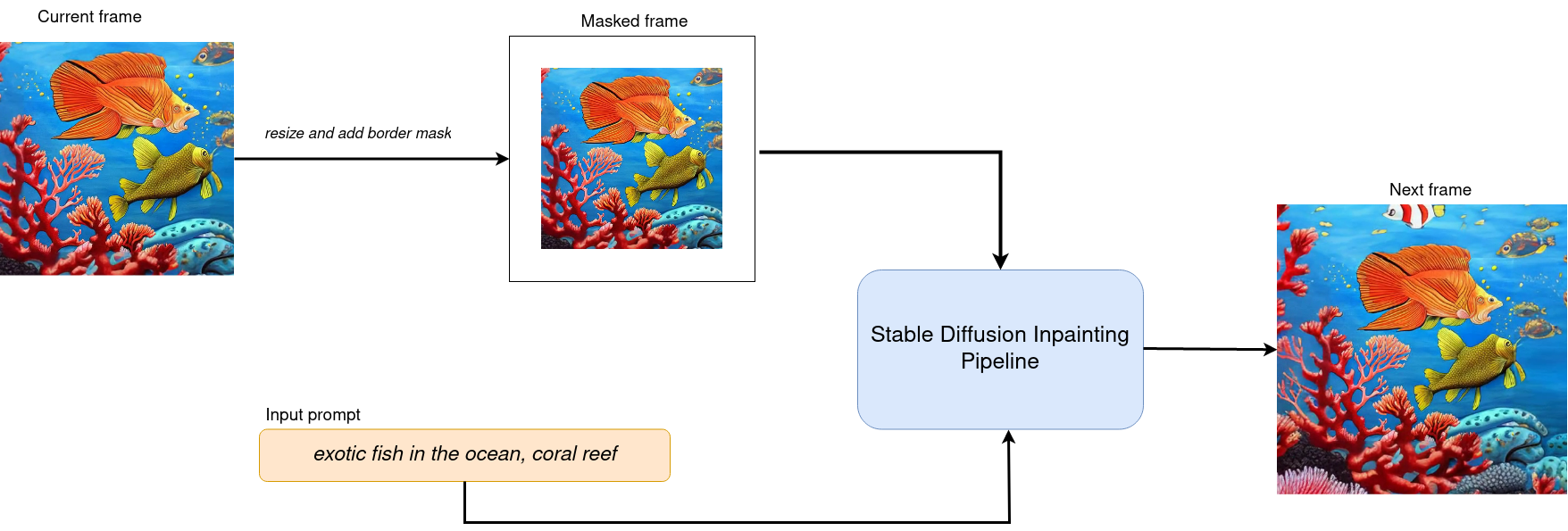\n", |
190 | 220 | "\n", |
|
208 | 238 | "from typing import List, Union\n", |
209 | 239 | "\n", |
210 | 240 | "import PIL\n", |
| 241 | + "from PIL import Image\n", |
211 | 242 | "import cv2\n", |
212 | 243 | "from tqdm import trange\n", |
213 | 244 | "import numpy as np\n", |
214 | 245 | "\n", |
215 | 246 | "\n", |
| 247 | + "def image_to_tensor(image: Image) -> ov.Tensor:\n", |
| 248 | + " pic = image.convert(\"RGB\")\n", |
| 249 | + " image_data = np.array(pic.getdata()).reshape(1, pic.size[1], pic.size[0], 3).astype(np.uint8)\n", |
| 250 | + " return ov.Tensor(image_data)\n", |
| 251 | + "\n", |
| 252 | + "\n", |
216 | 253 | "def generate_video(\n", |
217 | 254 | " pipe,\n", |
218 | 255 | " prompt: Union[str, List[str]],\n", |
|
251 | 288 | " mask_image = np.array(current_image)[:, :, 3]\n", |
252 | 289 | " mask_image = PIL.Image.fromarray(255 - mask_image).convert(\"RGB\")\n", |
253 | 290 | " current_image = current_image.convert(\"RGB\")\n", |
254 | | - " init_images = pipe(\n", |
| 291 | + " current_image = image_to_tensor(current_image)\n", |
| 292 | + " mask_image = image_to_tensor(mask_image)\n", |
| 293 | + " image_tensors = pipe.generate(\n", |
255 | 294 | " prompt=prompt,\n", |
256 | 295 | " negative_prompt=negative_prompt,\n", |
257 | 296 | " image=current_image,\n", |
258 | 297 | " guidance_scale=guidance_scale,\n", |
259 | 298 | " mask_image=mask_image,\n", |
260 | 299 | " num_inference_steps=num_inference_steps,\n", |
261 | | - " ).images\n", |
| 300 | + " )\n", |
| 301 | + " init_images = []\n", |
| 302 | + " for image_tensor in image_tensors.data:\n", |
| 303 | + " init_images.append(PIL.Image.fromarray(image_tensor))\n", |
262 | 304 | "\n", |
263 | 305 | " image_grid(init_images, rows=1, cols=1)\n", |
264 | 306 | "\n", |
|
284 | 326 | "\n", |
285 | 327 | " # inpainting step\n", |
286 | 328 | " current_image = current_image.convert(\"RGB\")\n", |
287 | | - " images = pipe(\n", |
| 329 | + " current_image = image_to_tensor(current_image)\n", |
| 330 | + " mask_image = image_to_tensor(mask_image)\n", |
| 331 | + " image_tensor = pipe.generate(\n", |
288 | 332 | " prompt=prompt,\n", |
289 | 333 | " negative_prompt=negative_prompt,\n", |
290 | 334 | " image=current_image,\n", |
291 | 335 | " guidance_scale=guidance_scale,\n", |
292 | 336 | " mask_image=mask_image,\n", |
293 | 337 | " num_inference_steps=num_inference_steps,\n", |
294 | | - " ).images\n", |
295 | | - " current_image = images[0]\n", |
| 338 | + " )\n", |
| 339 | + " current_image = PIL.Image.fromarray(image_tensor.data[0])\n", |
296 | 340 | " current_image.paste(prev_image, mask=prev_image)\n", |
297 | 341 | "\n", |
298 | 342 | " # interpolation steps bewteen 2 inpainted images (=sequential zoom and crop)\n", |
|
321 | 365 | " fps = 30\n", |
322 | 366 | " save_path = video_file_name + \".mp4\"\n", |
323 | 367 | " write_video(save_path, all_frames, fps, reversed_order=zoom_in)\n", |
| 368 | + "\n", |
324 | 369 | " return save_path" |
325 | 370 | ] |
326 | 371 | }, |
|
453 | 498 | "\n", |
454 | 499 | "from gradio_helper import make_demo_zoom_video\n", |
455 | 500 | "\n", |
456 | | - "demo = make_demo_zoom_video(ov_pipe, generate_video)\n", |
| 501 | + "demo = make_demo_zoom_video(pipe, generate_video)\n", |
457 | 502 | "\n", |
458 | 503 | "try:\n", |
459 | 504 | " demo.queue().launch()\n", |
|
0 commit comments