|
1 | | -# Zero-shot Image Classification with SigLIP |
| 1 | +# Zero-shot Image Classification with SigLIP2 |
2 | 2 |
|
3 | 3 | [](https://colab.research.google.com/github/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/siglip-zero-shot-image-classification/siglip-zero-shot-image-classification.ipynb) |
4 | 4 |
|
5 | 5 | Zero-shot image classification is a computer vision task with the goal to classify images into one of several classes without any prior training or knowledge of these classes. |
6 | 6 |
|
7 | 7 | 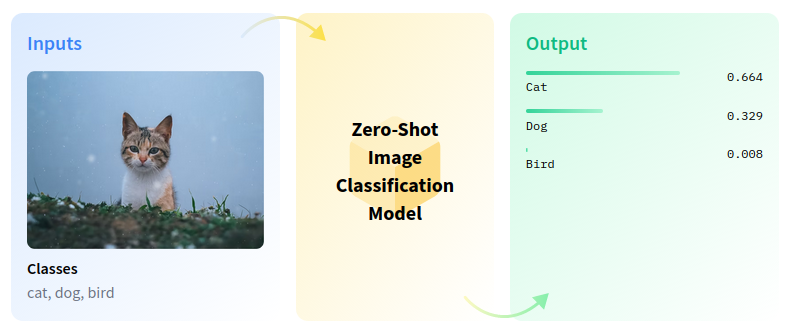 |
8 | 8 |
|
9 | | -In this tutorial, you will use the [SigLIP](https://huggingface.co/docs/transformers/main/en/model_doc/siglip) model to perform zero-shot image classification. |
| 9 | +In this tutorial, you will use the [SigLIP2](https://huggingface.co/blog/siglip2) model to perform zero-shot image classification. |
10 | 10 |
|
11 | 11 | ## Notebook Contents |
12 | 12 |
|
13 | | -This tutorial demonstrates how to perform zero-shot image classification using the open-source SigLIP model. The SigLIP model was proposed in the [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) paper. SigLIP suggests replacing the loss function used in [CLIP](https://github.com/openai/CLIP) (Contrastive Language–Image Pre-training) with a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet. |
| 13 | +The SigLIP model was proposed in [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343). SigLIP proposes to replace the loss function used in [CLIP](https://github.com/openai/CLIP) (Contrastive Language–Image Pre-training) by a simple pairwise sigmoid loss. This results in better performance in terms of zero-shot classification accuracy on ImageNet. |
14 | 14 |
|
15 | | -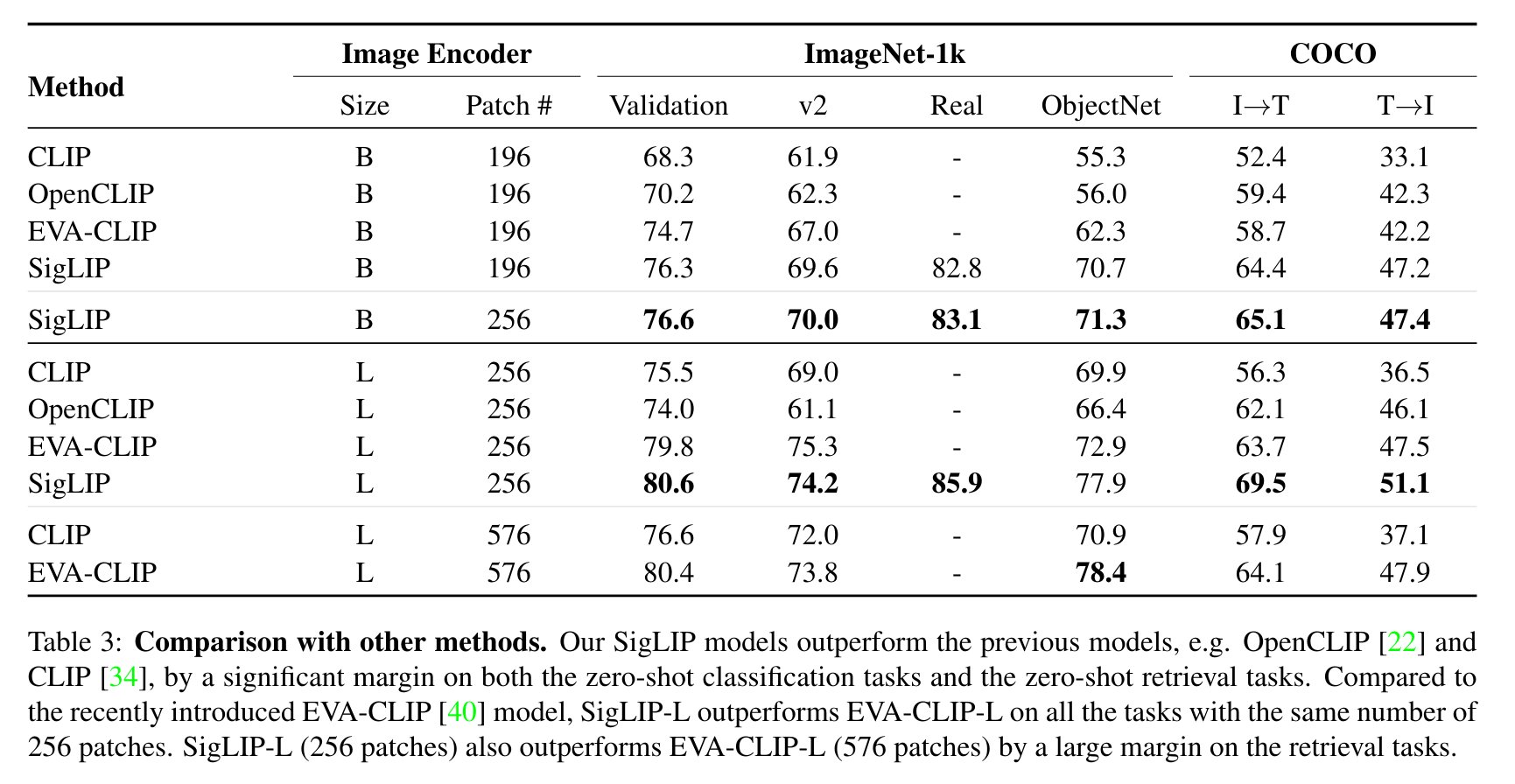 |
| 15 | +The abstract from the paper is the following: |
16 | 16 |
|
17 | | -[\*_image source_](https://arxiv.org/abs/2303.15343) |
| 17 | +> We propose a simple pairwise Sigmoid loss for Language-Image Pre-training (SigLIP). Unlike standard contrastive learning with softmax normalization, the sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. The sigmoid loss simultaneously allows further scaling up the batch size, while also performing better at smaller batch sizes. |
18 | 18 |
|
19 | 19 | You can find more information about this model in the [research paper](https://arxiv.org/abs/2303.15343), [GitHub repository](https://github.com/google-research/big_vision), [Hugging Face model page](https://huggingface.co/docs/transformers/main/en/model_doc/siglip). |
20 | 20 |
|
| 21 | +[SigLIP 2](https://huggingface.co/papers/2502.14786) extends the pretraining objective of SigLIP with prior, independently developed techniques into a unified recipe, for improved semantic understanding, localization, and dense features. SigLIP 2 models outperform the older SigLIP ones at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). More details about SigLIP 2 can be found in [blog post](https://huggingface.co/blog/siglip2) |
| 22 | + |
| 23 | +. |
| 24 | + |
| 25 | +SigLIP 2 models outperform the older SigLIP ones at all model scales in core capabilities, including zero-shot classification, image-text retrieval, and transfer performance when extracting visual representations for Vision-Language Models (VLMs). |
| 26 | +A cherry on top is the dynamic resolution (naflex) variant. This is useful for downstream tasks sensitive to aspect ratio and resolution. |
| 27 | + |
| 28 | +In this notebook, we will use [google/siglip2-base-patch16-224](https://huggingface.co/google/siglip2-base-patch16-224) by default, but the same steps are applicable for other SigLIP family models. |
| 29 | + |
21 | 30 | The notebook contains the following steps: |
22 | 31 |
|
23 | 32 | 1. Instantiate model. |
24 | | -1. Run PyTorch model inference. |
25 | | -1. Convert the model to OpenVINO Intermediate Representation (IR) format. |
26 | | -1. Run OpenVINO model. |
27 | | -1. Apply post-training quantization using [NNCF](https://github.com/openvinotoolkit/nncf): |
| 33 | +2. Run PyTorch model inference. |
| 34 | +3. Convert the model to OpenVINO Intermediate Representation (IR) format. |
| 35 | +4. Run OpenVINO model. |
| 36 | +5. Apply post-training quantization using [NNCF](https://github.com/openvinotoolkit/nncf): |
28 | 37 | 1. Prepare dataset. |
29 | | - 1. Quantize model. |
30 | | - 1. Run quantized OpenVINO model. |
31 | | - 1. Compare File Size. |
32 | | - 1. Compare inference time of the FP16 IR and quantized models. |
| 38 | + 2. Quantize model. |
| 39 | + 3. Run quantized OpenVINO model. |
| 40 | + 4. Compare File Size. |
| 41 | + 5. Compare inference time of the FP16 IR and quantized models. |
33 | 42 |
|
34 | 43 | The results of the SigLIP model's performance in zero-shot image classification from this notebook are demonstrated in the image below. |
35 | 44 |  |
|
0 commit comments