Flag the Repr::repr function with #[inline] #9032
Conversation
This allows cross-crate inlining which is *very* good because this is called a lot throughout libstd (even when libstd is inlined across crates).
|
It's not an issue with LLVM. If you mark a function as |
This allows cross-crate inlining which is *very* good because this is called a lot throughout libstd (even when libstd is inlined across crates). In one of my projects, I have a test case with the following performance characteristics commit | optimization level | runtime (seconds) ----|------|---- before | O2 | 22s before | O3 | 107s after | O2 | 13s after | O3 | 12s I'm a bit disturbed by the 107s runtime from O3 before this commit. The performance characteristics of this test involve doing an absurd amount of small operations. A huge portion of this is creating hashmaps which involves allocating vectors. The worst portions of the profile are:  Which as you can see looks like some *serious* problems with inlining. I would expect the hash map methods to be high up in the profile, but the top 9 callers of `cast::transmute_copy` were `Repr::repr`'s various monomorphized instances. I wish there we a better way to detect things like this in the future, and it's unfortunate that this is required for performance in the first place. I suppose I'm not entirely sure why this is needed because all of the methods should have been generated in-crate (monomorphized versions of library functions), so they should have gotten inlined? It also could just be that by modifying LLVM's idea of the inline cost of this function it was able to inline it in many more locations.
{kind=link}
|
It seems weird though because wherever |
|
There are no guarantees about inlining those, because there are undefined bitcasts from |
|
Can you replicate it with |
|
I cannot replicate it with no-monomorphic-collapse, interesting. The runtime goes from 23s => 11s with that flag. |
|
Yep, so it's just from undefined behaviour in our IR. |
|
There was talk of removing that part of the compiler, right? |
|
Yes, but it hasn't happened. The |
enum_variant_names should ignore when all prefixes are _ close rust-lang#9018 When Enum prefix is only an underscore, we should not issue warnings. changelog: fix false positive in enum_variant_names
This allows cross-crate inlining which is very good because this is called a
lot throughout libstd (even when libstd is inlined across crates).
In one of my projects, I have a test case with the following performance characteristics
I'm a bit disturbed by the 107s runtime from O3 before this commit. The performance characteristics of this test involve doing an absurd amount of small operations. A huge portion of this is creating hashmaps which involves allocating vectors.
The worst portions of the profile are:
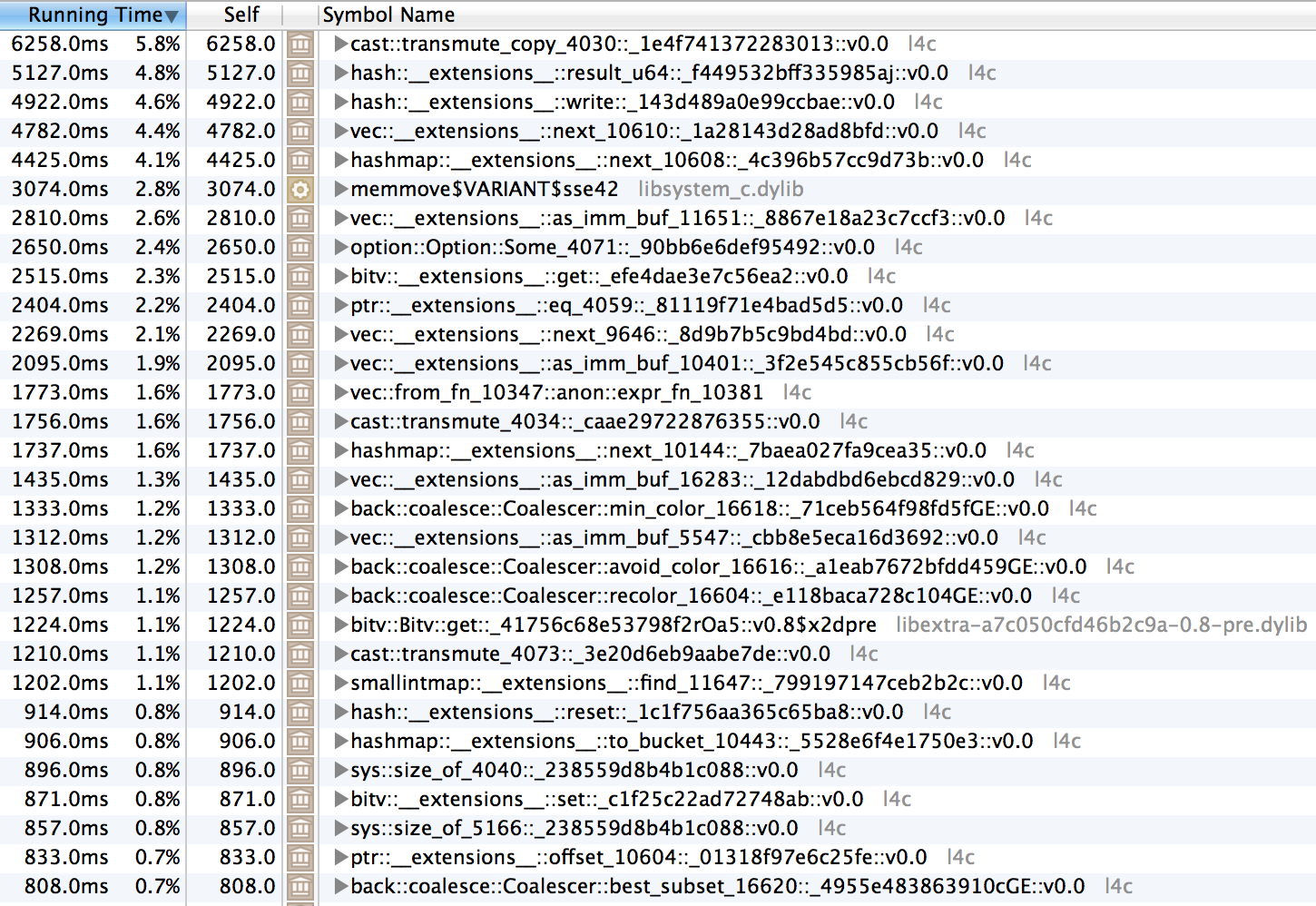
Which as you can see looks like some serious problems with inlining. I would expect the hash map methods to be high up in the profile, but the top 9 callers of
cast::transmute_copywereRepr::repr's various monomorphized instances.I wish there we a better way to detect things like this in the future, and it's unfortunate that this is required for performance in the first place. I suppose I'm not entirely sure why this is needed because all of the methods should have been generated in-crate (monomorphized versions of library functions), so they should have gotten inlined? It also could just be that by modifying LLVM's idea of the inline cost of this function it was able to inline it in many more locations.